Observing AI Entering Astrophysics:A Series Introduction and Request for Perspectives

Astronomy may be the natural science which AI rewires first. Its infrastructure is unusually open. Most data is public. The scientific record is mostly open through online preprint servers. Core software is open-source. Nearly every step of the workflow is digitalized. This reduces friction for AI agents to participate.
This is the first in a series of posts documenting how AI is entering astrophysics. It is also a request. If you are an astronomer (or a scientist in related fields) at any career stage, I want to hear how AI is showing up in your work. A short written reflection, a comment below, or a video call — all are welcome. Contributions can be anonymous. No one from private communication will be quoted without permission.
I am a former astrophysicist. After a PhD and postdoc in astrophysics, I pivoted to work on questions of scientific integrity in topics as down-to-earth as herbicides, and I am completing a second PhD in science, technology and society. Conducting my current research with AI assistance feels like a different kind of intellectual experience from my work in the pre-AI era. That contrast, together with a view from both worlds, is what motivates this series.
Voices around the emergence of AI in science range from deep enthusiasm to outright skepticism. That alone suggests this moment is worth recording before we settle into whichever “new normal” comes next.
Is this moment akin to previous technological revolutions or is there anything qualitatively different? Some historical context is warranted and is briefly outlined next.
The beginning of computers in astrophysics
The experience of a junior researcher in astronomy today is drastically different from that of a retired professor. The technological advances in integrated electronics within just the last ~60 years have transformed the field. Those changes include the introduction of numerical modeling, digitized observations and computer-mediated communication. What follows is by no means a comprehensive historical recap, but rather a few vignettes of lived experience.
Computation and simulation
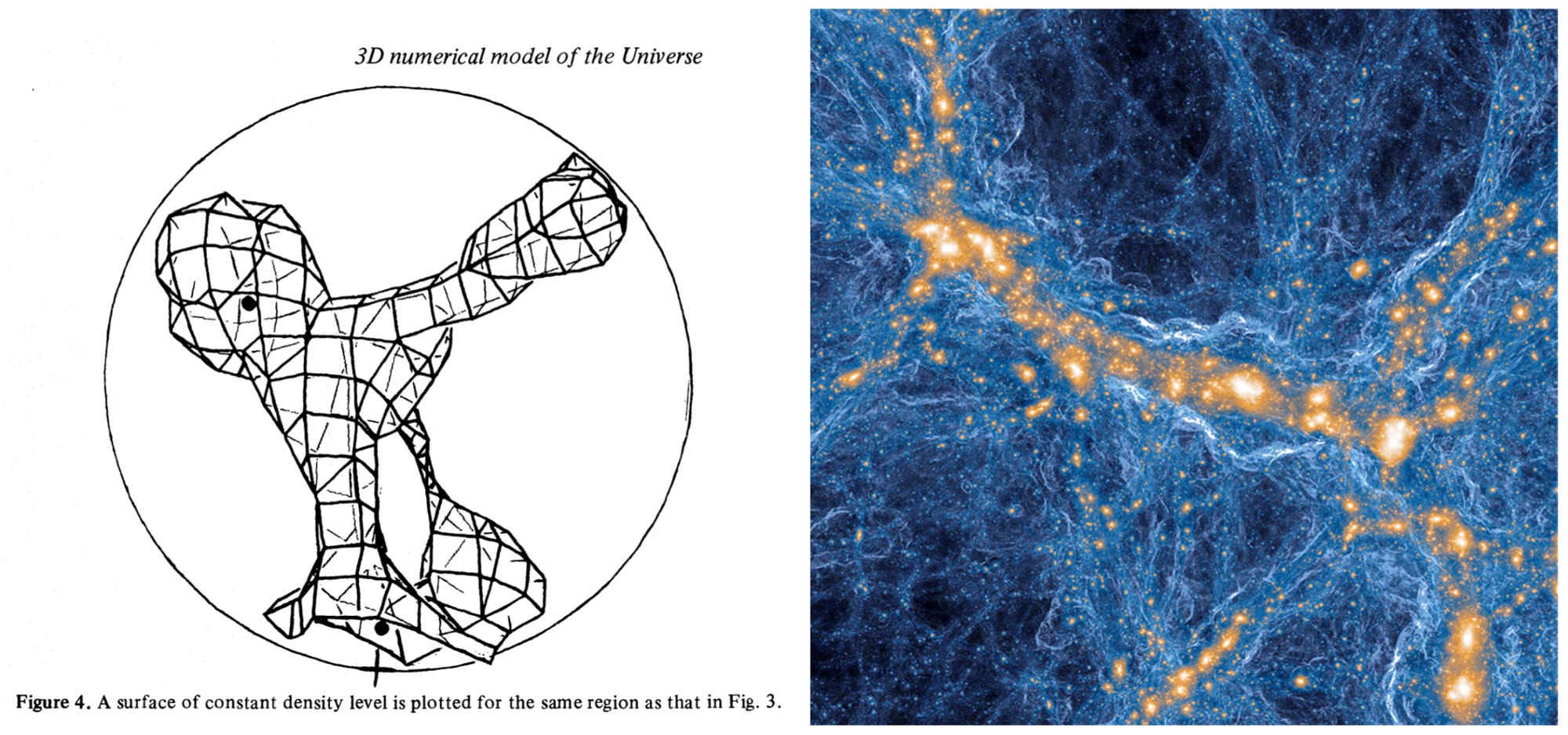
Numerical simulation on digital computers entered professional astronomy through N-body gravitational problems—an astrophysics-specific challenge that tries to solve many particles, usually stars, orbiting each other. This problem can be solved classically on paper, but only for N=2 and in some special forms for N=3. It was targeted already in the 1960s (e.g., von Hoerner, 1960), and the scale of flagship simulations has since grown dramatically.
The researchers were cautious. In 1964, Richard Miller (1926-2020), one of the pioneers of computational astrophysics, wrote explicitly that “[a]s with any experimental arrangement, the experimenter using numerical methods must demonstrate the applicability and validity of his results”, and proceeded describing one of the numerical issues of exponential growth of numerical errors.
As computation became more accessible inside academic institutions, it altered not only what could be calculated but how research time was structured. Piet Hut, for instance, recalls arriving at the Institute for Advanced Study (IAS) in 1981 the same week a new computer arrived, and how he gained access to a personal terminal. It was an upgrade from programmable calculators that required running a single trajectory calculation overnight. Around that time most of "human computer" positions—that is to say, people, often women, who performed computations—became obsolete.
Limitations of the early computers did not hinder the ambitions of researchers. For instance, in 1983, Anatoly Klypin and Sergei Shandarin (1947-2025) modeled a box of 500 Million light years across with just 30,000 particles.
Adoption of computational astrophysics spread beyond N-body problems. For instance in 1985, W. David Arnett in his forward‑looking optimistic reflection wrote that "computational astrophysicists will be able to find out more about stellar evolution and other astronomical phenomena".
Detectors, surveys, and the "big data"
In parallel, observational hardware was disrupted as well. Charge‑coupled devices (CCDs), invented in 1969, had largely replaced photographic plates by the 1990s (and soon after replaced consumer film photography). The transition did not merely improve sensitivity; it pushed astronomers further away from the telescopes, making physical presence next to the telescope more and more unnecessary. This, in turn, increasingly divorced data products from any single observer's embodied experience at the telescope.
The professional ecosystem around older technologies could also collapse quickly. In 1994, David Malin reflected on the end of an era in which Kodak had been a standard presence at astronomy meetings, after the company terminated a long‑standing line of photographic products made for astronomers. Malin pondered, "The final question remains. Is it worth persisting with photography? Of course"—arguing that under some circumstances it still was.
Computerization also enabled automation at scale. Surveys such as the Two‑Degree Field survey (2dF, 1997–2002) and the Sloan Digital Sky Survey (SDSS, 2000–ongoing) institutionalized systematic sky coverage and created long‑lived public data sets. Contemporary astronomy extends this "big data" era further through space missions such as Gaia and through facilities designed around data‑intensive workflows (e.g., the Vera C. Rubin Observatory's Legacy Survey of Space and Time). In this setting, computation is not optional; it is constitutive.

Communication infrastructure and openness
At the same time, advances in communication infrastructure allowed the field to move from paper preprints circulated among libraries to email lists in the 1980s like the one maintained by Joanne Cohn for theoretical physics, and then to automated preprint distribution via arXiv, launched by Paul Ginsparg in 1991. Whatever one thinks about the downstream consequences on the peer-review and publishing industry, arXiv helped make the research record in theoretical physics and astronomy open by default.
Taken together, these shifts produced a scientific culture in which much of the workflow is digital, most data are public, and core computational tools are open-source. It is difficult to imagine a more welcoming environment for AI agents.
Recurring concerns: skill and epistemic trust
These transitions were not frictionless. Many of the concerns they raised reappear today in debates about AI.
Two recurring practical interconnected concerns are de‑skilling and specialization. In the context of astronomical photography, Malin wrote in 1988 that the "age of specialisation" had arrived and remarked on the risk that newer generations might forget the material roots of older techniques based on the "unpleasant brown liquids" of darkroom chemistry. The broader pattern is familiar: as technical stacks become more complex, researchers with finite time and attention often face a choice between becoming specialized tool‑builders (i.e. software engineers, instrument scientists) or becoming users of increasingly opaque systems (Mäki-Reinikka, 2018). Few can hold deep, end‑to‑end expertise across all domains of modern astronomy.
One senior astrophysicist who witnessed the field's reorganization described it in private conversation as the "industrialization of astrophysics." Researchers are pushed into ever-narrower specializations until they resemble conveyor-belt workers. The overproduction of PhDs, in astronomy and across the sciences, is consistent with this pattern of training more specialists than the system can absorb and making each individual more disposable. These trends are not unique to science. Sociologists of labor recognized similar dynamics across other industries, treating deskilling and routinization as structural features of modern work rather than incidental side effects of new technology.
Another set of concerns is epistemological: where do trust and knowledge reside?
One of them is data. Even when new detectors outperform old ones, the locus of "seeing" shifts. Much of what we claim to know about the sky is mediated through pipelines and catalogs; many of the billions of objects we name are never inspected directly by a human eye. Morry Koman's First Light is an artistic statement of this condition: the archive is vast, and "observation" increasingly means structured records rather than personal inspection.
Numerical modeling, or simulations, is another one. It is now a common mode of astrophysical inquiry, and the field has developed norms for treating simulations as credible (and for knowing when not to). These norms take many forms. One example is ensemble modeling — running many realizations of a system with different initial conditions and comparing the resulting distribution statistically against observations (a form of simulation-based inference). Another is community code comparisons, in which independent teams implement the same agreed-upon physics and compare outputs. When results diverge, the mismatch exposes an additional layer of ambiguity: not in the equations themselves, which are well established, but in the numerical choices made to solve them.
Already in 1950, Douglas Hartree (1897-1958) outlined "some psychological problems in numerical analysis," suggesting that one must on one hand "overcome the attitude of the mathematical fraternity toward the subject" but also the necessity to develop "feeling and intuition for the way calculations are going," which could be done by "[carrying] out the evaluation of one solution by hand."
AI entering astronomy: what is qualitatively new
By the late 2000s, Machine Learning had begun to permeate astronomy in earnest. Before, even the most complex numerical simulations had authors of the code who understood, ideally, its every line. There was a human intentionality behind those instructions. Machine-learning techniques are also deterministic and written by humans; however, the process of training removed a certain degree of certainty about how the system operates and limited our ability to debug it. These "Black box" concerns were (and still are) real. In practice, many machine-learning methods persisted because there is a class of tasks in which they consistently outperform standard approaches. And there are arguably other societal and career reasons that push scientists towards these tools.
What has changed more recently with AI is scope.
Large language models (LLMs) and tool‑using agentic systems make AI less a single technique and more an environment: something that can draft and refactor code, summarize and map literatures, propose hypotheses, design analysis plans, and chain these steps together. This is a different kind of integration than a machine-learning model serving as a classifier in the pipeline. AI now reaches into nearly every aspect of scientific work: authorship and credit, what counts as expertise, pedagogy and mentorship, peer review, and grant writing.
Within my former professional circle, the spread of AI adoption and concerns is palpable.
Around 2019, while I was an astrophysics postdoc at the IAS, we had small machine‑learning meetings. During one of them, Yuan‑Sen Ting described transformers as "the next big thing." I did not fully appreciate the significance at the time. Now transformers are ubiquitous, popularized well beyond specialist circles through the abbreviation "GPT" (Generative Pre‑trained Transformers). Yuan‑Sen Ting has since continued to study AI in astronomy, including what "understanding" means in AI‑laden astronomical practice.
Francisco Villaescusa‑Navarro, who was also at those 2019 meetings, now works on Denario, described as an AI multi‑agent system designed to serve as a scientific research assistant. These are not the only examples, but they illustrate the shift: AI is increasingly treated not merely as a method for classification or regression, but as something closer to an infrastructural layer for research.
In early 2026, the accelerated adoption of LLM tools and agentic workflows is difficult to miss. Scott Dodelson has described his experience with AI as "a powerful, visceral experience" that will take time to process. David Hogg has circulated a white paper—"Why do we do astrophysics?"—that reflects on what LLMs may do to the field. Recent work by Alfredo Guevara (IAS) and collaborators, which treats ChatGPT as effectively a co‑author, has been featured by OpenAI. One can disagree with the framing of any of these examples; but the point is the wide uptake of AI tools.
Does AI represent more of the same — another powerful technology absorbed into astronomy's workflow — or is something qualitatively different underway?
In the case of the latter, the uncertainty is vast. Will AI enable more people to do research in astronomy — or discourage them by making it seem there is nothing left to contribute? Will it erode public trust in science, or strengthen it? Will it pollute the published record to the point where consensus becomes harder to reach? These are not the only questions, but they suggest the range of what is at stake.
What this series will be — and an invitation
This series will explore these questions through conversations, interviews, and close readings of public material — staying true to what people actually report while contextualizing it for a wider academic and professional audience.
If you have thoughts, experiences, or worries about AI in astronomy and astrophysics — whether enthusiastic or skeptical — I would like to hear from you. I am also interested in perspectives from neighboring fields (physics, statistics, computer science, engineering, mathematics).



